
 No cabe duda de que en gran parte las personas lo somos en tanto que utilizamos un lenguaje. Las palabras que decimos o que escribimos se convierten en una huella que dice mucho de cada cual. Por supuesto que no solo somos palabra pero es cierto que cuando se puede acceder a grandes volúmenes de lo que una persona dice o escribe, podemos «fotografiar» casi en modo automático a ese ser humano en cuestión. Ya escribimos de ello hace poco.
No cabe duda de que en gran parte las personas lo somos en tanto que utilizamos un lenguaje. Las palabras que decimos o que escribimos se convierten en una huella que dice mucho de cada cual. Por supuesto que no solo somos palabra pero es cierto que cuando se puede acceder a grandes volúmenes de lo que una persona dice o escribe, podemos «fotografiar» casi en modo automático a ese ser humano en cuestión. Ya escribimos de ello hace poco.
Sí, en este blog ya hemos escrito en varias ocasiones del análisis masivo de texto. Pues bien, ayer tuve una estupenda conversación con una compañera de la facultad de ingeniería de mi universidad que está trabajando en el procesamiento del lenguaje natural. En su caso ella proviene del campo de la informática y sus conocimientos -tengo que reconocerlo- me apabullaban un poco. Está con su ¡segundo doctorado! centrado en esto del big data aplicado al procesamiento del lenguaje.
El caso es que nuestra humilde investigación se convierte en un tesoro de considerable valor por cuanto toma los datos de lo que sucede en un foro de discusión en Internet. Esto elimina (aunque a veces pueda parecer difícil de creer cuando hablamos ya de cerca de 40.000 mensajes) mucho ruido en la conversación. Frente a lo que se dice en las redes sociales generalistas, en un foro de discusión la temática está muy focalizada y eso hace que el trabajo de minería, aislando lo que se denominan stop words (palabras vacías de contenido), sea mucho más fructífero.
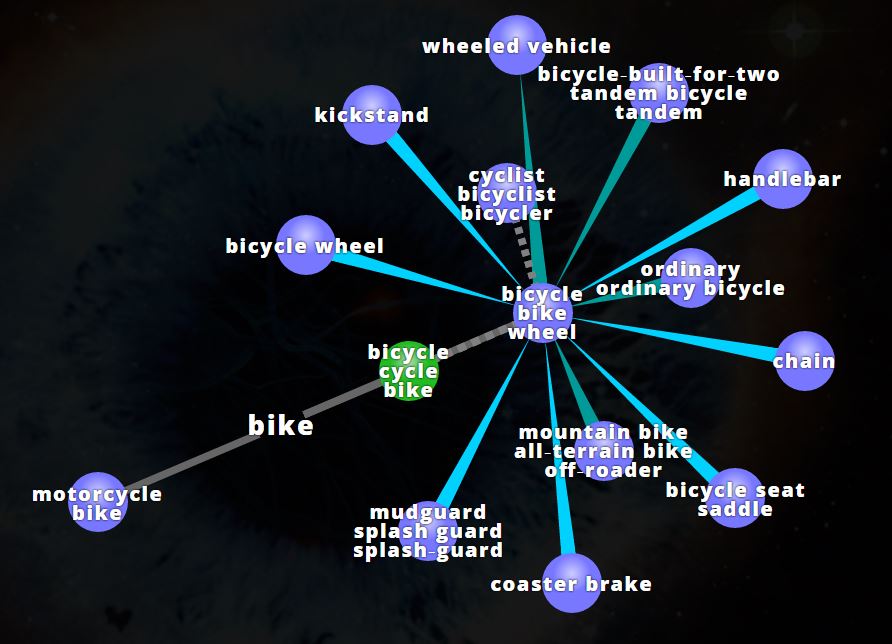
Además, el número de herramientas para sondear en volúmenes elevados de texto es cada vez mayor. Sí que es necesario apoyarse en ontologías para que las herramientas hagan bien su labor pero ya existen trabajos útiles para que ese análisis de los conceptos no parta desde cero. Visuwords es, por ejemplo, una herramienta gratuita que sirve para visualizar conceptos. Es un diccionario visual que permite relacionar mediante diferentes conectores todo un universo de palabras que gira en torno a algo. Para que os hagáis una idea, adjunto una imagen del resultado que se obtiene al buscar «bike» en este particular diccionario visual.
En nuestra investigación, como quiera que tenemos acceso a volúmenes importantes de texto, podemos utilizar este tipo de análisis u otros muy similares para extraer valor de las conversaciones sin necesidad de leerlas. No obstante, lo lógico es, como decíamos hace unos días, complementar dato cuantitativo con metodología cualitativa. Así lo estamos haciendo. Espero que lleguemos a conclusiones útiles con tanto dato 🙂
Preguntas de neofito inquieto en la materia: 1) Si el foro tiene mas foco tematico, el ratio señal/ruido mejorara tanto que habra que afinar mucho mucho el filtro anti-ruido, no, para no generar falsos negativos? (Intuyo q con ratios señal/ruido muy malos, el filtro anti-ruidos es mas productivo y eficaz), 2) Mi precaria experiencia con herramientas de visualizacion de datos es un poco frustrante. Esos mapas quedan bonitos, dan el pego, pero en mi caso no me han revelado «secretos» (conexiones o temas relevantes) que no conociera, ¿te esta pasando eso y la visualizacion te esta descubriendo pistas novedosas?, 3) Me interesa muchisimo el tema de las ontologias. Pregunto: ¿tienes que construir tu mismo una «ontologia especializada» para el tema de las bicis o basta con usar los paquetes estandar? Son temas que me producen curiosidad. Igual puedes responderme con un post, si lo prefieres…
Amalio, no creas que tengo las respuestas claras. Pero voy con ello y ya escribiremos con más conocimiento de causa en breve si me meto más en este mundo del big data aplicado al análisis y procesamiento del lenguaje.
Respecto a lo primero, no sé si te entiendo bien. El foro constituye una muy buena materia prima porque ya ha focalizado sobre un tema. Sin embargo, todos usamos palabras que no aportan valor. Nos importan sobre todo sustantivos, adjetivos y adverbios. Los primeros indican conceptos y los segundos la valoración de los conceptos. Pero para que la herramienta de análisis masivo trabaje bien hay que eliminar las stop words o palabras vacías. Ya hay «paquetes» que te eliminan esas palabras pero luego hay que ir a mano eliminándolas. Por ejemplo, en lo que estoy analizando palabras que se repiten mucho y que pueden seer stop words: jeje, jajaja y variantes, que haberlas haylas. Además, mediante steming se pueden agrupar palabras con la misma raíz. Hay mucho trabajo de cocina por detrás.
La visualización hay que trabajarla porque sí o sí la interfaz para la empresa tiene que resumir lo que los datos aportan y hacer más probable que decidan en base a ellos. Si no se consigue dar con ella, todo el trabajo de fondo puede ir a la basura. Por muy frustrante que pueda ser la experiencia, hay que trabajarlo. No queda otra.
En cuanto a lo tercero, las ontologías en su mayor parte hay que construirlas porque en muchas casos son muy específicas. Imagina por ejemplo que quieres evaluar cómo un usuario «siente» el sistema de amortiguación de una bici de doble suspensión. Hay que hacer una relación de adjetivos/adverbios asociados a esa sensación. Cuanto más partido quieras sacar del análisis, más hay que trabajar las ontologías.
Bueno, espero más o menos haberme explicado. Seguro que postearé algo más al respecto. De todas formas, no quiero entrar aquí y prefiero dejarlo como una futura línea de investigación, porque es un mundo en sí mismo 🙂
Sobre las ontologías, mira en http://linkeddata.org/ Lo mejor es antes de definir nada comprobar lo que se pueda reaprovechar (es uno de los intereses principales de las ontologías: que sea un vocabulario común)
Y también pueden servir enfoques desde el punto de vista de las redes complejas https://arxiv.org/pdf/1606.09636.pdf https://arxiv.org/pdf/1302.4490.pdf
Mil gracias por el aporte, Miguel. Lo de no reinventar ruedas es básico y partir de trabajos ya realizados es fundamental. Lo que comentas me lleva pensar si algún día sería posibles una wikipedia de ontologías… o algo parecido 😉